Safe Reinforcement Learning via Probabilistic Logic Shield
A deep reinforcement learning framework that ensures safety of the learning agent by applying logical constraints on the neural policy.
[Paper] [Code] [Poster] [Bibtex]
Some figures in this blog post are generated using DALL.E.
Safety in AI (a very soft intro)

Ellen had heard a lot about the new self-driving cars, and while the idea of being able to sit back and relax while her car took her where she needed to go sounded appealing, she wasn’t sure if she could trust the technology. She made her way to the nearest self-driving car service station and climbed into the back seat of the sleek, futuristic vehicle. The car pulled away from the curb, merged into traffic and navigated the busy city streets with ease, smoothly weaving in and out of traffic and coming to a stop at each red light without hesitation.
As the car approached a busy intersection, Ellen heard the sound of sirens in the distance. An ambulance came into view, speeding down the road with its lights flashing. Ellen’s self-driving car hesitated for a moment, and then made the decision to run the red light and pull over to the side of the road, making way for the ambulance. Ellen was impressed by the car’s quick thinking, and felt a newfound sense of trust in the technology. As the ambulance passed by, she could see the paramedics inside, working to save the life of the patient. She realized that the self-driving car had made the right decision, prioritizing the safety of others even at the risk of breaking the law.
Ellen began to relax, even enjoying the ride. All of a sudden, a screech of tires and the sickening sound of metal colliding with metal pierced the air. In an instant, Ellen’s car had been T-boned by another vehicle. She was thrown violently to the side, and when she looked up, she saw that the other car was a self-driving vehicle as well. It had apparently failed to stop at a red light and had plowed into Ellen’s car.
The self-driving car scenario demonstrates the need for a machine learning system that can reason about complex, dynamic environments and make decisions based on uncertain and incomplete information. In such a scenario, the system must be able to understand and navigate a world that consists of many types of objects such as cars, traffic lights, intersections and people that can move over time. The system must also be able to handle heterogeneous data from multiple sources, such as LiDAR, real-time traffic information and geographical maps. The system must be able to combine short-term actions and long-term planning. For example, the self-driving car should follow a route to a destination within a reasonable period of time, taking into account potential obstacles on the way.
Most importantly, intelligent systems should prioritize safety in order to earn public trust. If an ambulance with sirens and flashing lights is approaching, the system should be able to infer that it is likely on a mission and that in some situations, it would be safe to run a red light in order to make way for the ambulance.
Intelligent systems can, and should, provide quantitative metrics and evaluations so that safety can be demonstrated and improved.
Driving safely using a shield: Why not?
Shielding is a popular Safe Reinforcement Learning (Safe RL) technique that aims at finding an optimal policy while staying safe. To do so, it relies on a shield, a logical component that monitors the agent’s actions and rejects those that violate the given safety constraint.
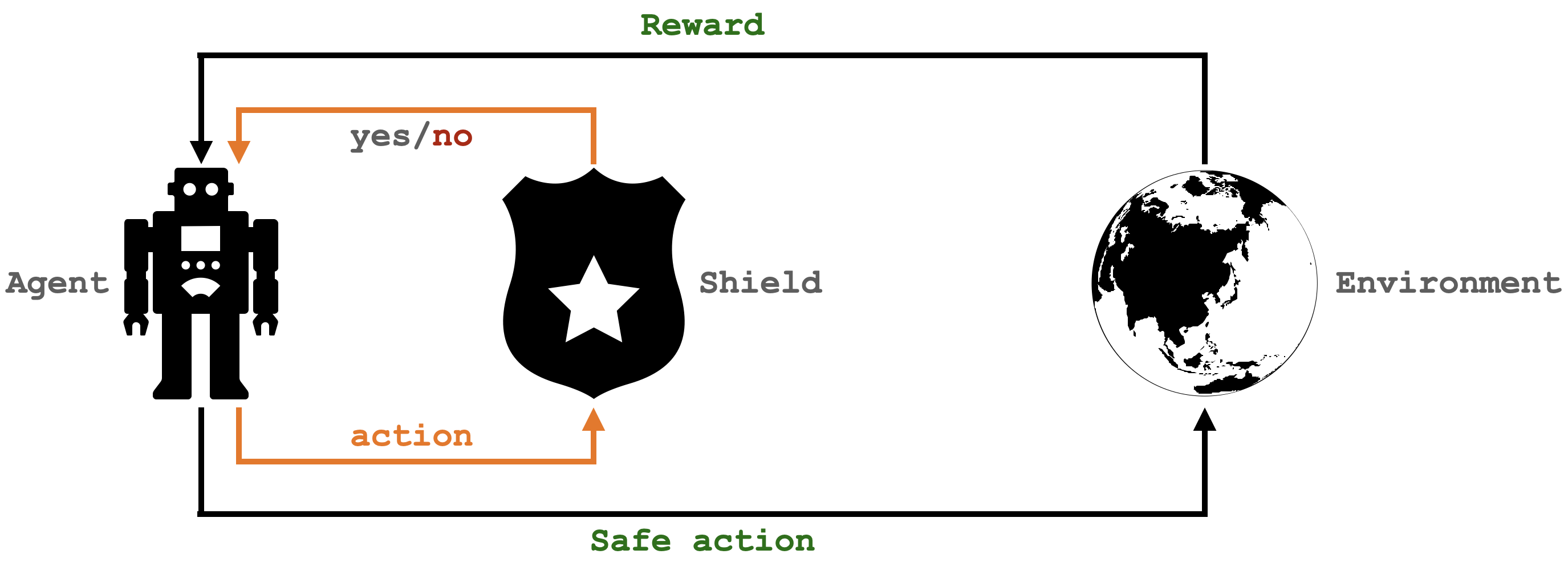
While early shielding techniques operate completely on symbolic state spaces, more recent ones have incorporated a neural policy learner to handle continuous state spaces. In this blog, we will also focus on integrating shielding with neural policy learners. A main difference of our work is that our neural policy takes as input an image (such as the following figure) instead of a symbolic representation.

Consider a self-driving agent that encounters a red light and another vehicle in front to its right. The agent is implemented as a neural network that takes visual input and produces a policy, i.e. a probabilistic distribution over actions {do-nothing, accelerate, brake, turn-left, turn-right}. The agent samples actions from this policy until it finds one that is accepted by the shield. In this scenario, the shield determines that accelerating or turning right is unsafe and will only accept actions in {do-nothing, brake, turn-left}. For example, the agent’s policy could be:
0.1::do-nothing,
0.5::accelerate,
0.1::brake,
0.1::turn-left,
0.2::turn-right
The agent samples the first action accelerate, which is rejected by the shield. The agent samples the second action accelerate, which is also rejected by the shield. Then, the agent samples the third action turn-left, which is accepted by the shield. The agent controls the vehicle to turn-left and receives a reward of +5.
This seems okay at first glance, however, this framework is too simple to capture many aspects of the real world.
- Not all actions are completely safe or unsafe. In fact, no actions are completely safe in driving scenarios.
- Sensors can be noisy and not deterministic, for example, the sensor may detect an obstacle with a probability of 0.4.
- The shield requires an accurate environment model, which is not always available, such as knowing road conditions, weather, and friction.
- Traditional shielding techniques can be difficult to integrate with continuous, end-to-end deep reinforcement learning methods.
- Even with perfect safety information in all states, rejection-based shielding may fail to learn an optimal policy. It may result in an extremely safe but non-rewarding policy that always stays put.
To mitigate the these issues, we must answer two questions:
- How can the shield capture uncertainties in the real world?
- How should the interface between the agent and the shield be expanded to incorporate both uncertainty and safety?
More ideal: being safer by using a probabilistic shield
A more ideal learning process may look like this: Consider the same scenario, but now the shield has probabilistic perception to detect the probability of there being an obstacle. The first rule states “the probability of there being an obstacle in front is 0.8.”
0.8::obstacle(front).
0.2::obstacle(left).
0.5::obstacle(right)
The shield incorporates the perception into its safety knowledge. The first rule is an if-else statement, stating that “if there is an obstacle in front, and the agent accelerates, then a crash will occur with a probability 0.9.”
0.9::crash:-obstacle(front), accelerate.
0.4::crash:-obstacle(left), turn-left.
0.4::crash:-obstacle(right), turn-right.
By combining agent’s policy, shield’s perception and safety knowledge, we obtain a safer policy:
0.17::do-nothing,
0.24::accelerate,
0.17::brake,
0.15::turn-left,
0.27::turn-right
Let’s analyze, informally, why this policy is safer:
- The probability of safer actions, i.e. do-nothing, brake, and turn-left, is higher.
- The probability of accelerate is 50% lower given:
- a high probability (0.8) of an obstacle in front
- a high probability (0.9) of a crash if accelerating
- The probability of turn-right is only slightly higher given:
- a probability (0.5) of an obstacle on the right
- a probability (0.4) of a crash if turning right
Using this safe policy, the agent will sample and perform an action in the environment. This shielding process provides a more realistic safety measure by integrating safety and uncertainty.
Probabilistic Logic Shields
We propose probabilistic shields as an alternative to the deterministic rejection-based shields. Essentially, probabilistic shields take the original policy and noisy sensor readings to produce a safer policy, as demonstrated below.
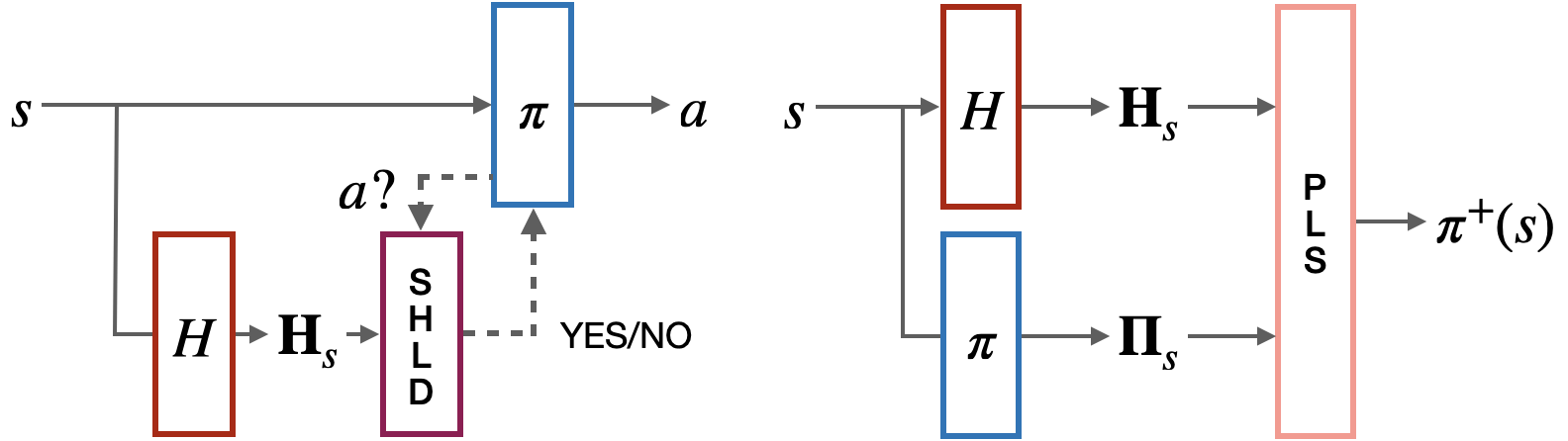
We focus on probabilistic shields implemented through probabilistic logic programs. Although we are using the probabilistic logic programming language ProbLog to reason about safety, we could also have used alternative representations such as Bayesian networks, or other StarAI models. The ProbLog representation is however convenient because it allows to easily model planning domains, it is Turing equivalent and it is differentiable.
By explicitly connecting action safety to probabilistic semantics, probabilistic shields provide a realistic and principled way to balance return and safety. This also allows for shielding to be applied at the policy level instead of at the individual action level, which is typically done in the literature.
For the details of our method, please check out the paper.